El otro dia estaba pensando escribir un
blog utilizando PowerBuilder, pero no podia decidirme sobre con que otra
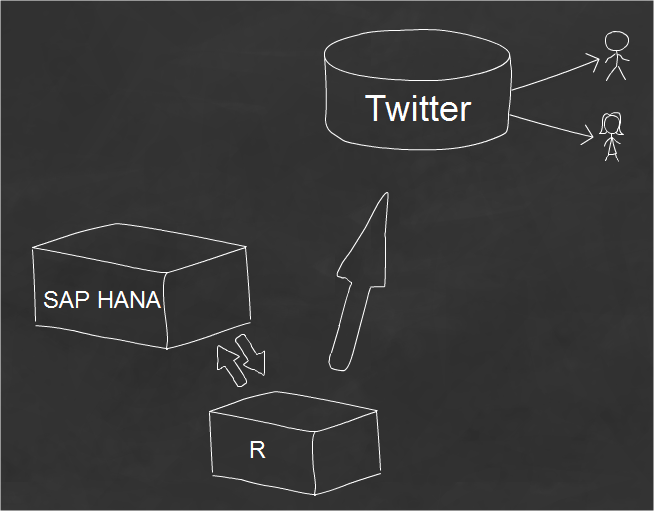
tecnologia podia integrarlo...por supuesto...R me vino a la mente...
Mi
viaje comenzo hace 4 dias...cuando comence a buscar formas de llamar a R desde
un lenguaje externo...la ultima vez utilice
Rook y
Heroku para llamar a R desde SAP Mobile Platform tal como se
explica en mi blog
Consuming R from SAP Mobile Platform, pero esta vez sabia que
tenia que hacer la cosas de una manera diferente.
Mi primera idea fue la
de utilizar
Rserve que es un servidor de R utilizado por SAP HANA Studio
para conectarse a R tal como se explica en mi blog
When SAP HANA met R - First kiss, asi que me descargue los
archivos de
REngine que son dos .jar de Java.
Para poder
conectarnos a Rserve necesitamos configurarlo...asi que basicamente con el
paquete Rserve instalado en mi
RStudio simplemente necesite crear un simple
archivo...
| Call_Rserve.R |
library("Rserve")
Rserve()
|
|
Cuando lo ejecutamos...El servidor de R va a
iniciarse como un proceso que puede ser visto en el Task Manager.
Con los
archivos listos, me fui a PowerBuilder y simplemente los agrege en el classpath
de Java tal como hice para el conector jdbc de SAP HANA tal como se explica en
mi blog
PowerBuilder - The new kid on Developer Center's block, no
funciono...los archivos estaban en el classpath pero no podia llamar a ninguno
de los metodos...asi que decidi seguir buscando alternativas y me encontre
con
Rcaller, un solo archivo .jar de Java que en vez de utilizar
Rserve, llama directamente al ejecutable de R...tampoco funciono...la cosa
es...en PowerBuilder (con la excepcion del connector jdbc de SAP HANA) necesitas
utilizar el
EAServer o un servidor que soporte EJB como
JBoss...yo nunca he utilizado
ninguno de los dos...ademas de que necesitas construir el archivo .jar tu mismo
pues se necesita informacion adicional.
Tenia la impresion de que estaba
llegando a un callejon sin salida...pero luego pense..."Hey...Estoy utilizando
PowerBuilder.NET!" lo cual significa obviamente que se basa en el
.NET Framework...lo cual
significa que podia utilizar archivos dll de .NET...pero yo solo tenia archivo
.jar de Java...
Haciendo un poco mas de investigacion me encontre
con
IKVM que es una
aplicacion que nos permite convertir cualquier archivo .jar de Java en un bonito
.dll de .NET...el uso es bastante simple...
| Using IKVM |
Open CMD
C:\>ikmvc -out:Rcaller.dll -target:module Rcaller.jar
|
|
Esto va a producir un archivo .dll llamado
Rcaller.dll...pense que estaba en el camino correcto asi que inclui este archivo
en mis referencias...no funciono puesto que lastimosamente, IKVM aun esta en
desarrollo y no todo de Java has sido traducido a .NET, como por ejemplo la
interfaz Java.IO...luego converti los dos archivos REngine .jar de Java en un
solo .dll pero tuve la misma suerte...algunas traducciones no estaban
presents...
De vuelta a Google a seguir buscando...esta
vez...directamente en implementaciones .NET y encontre
R.NET que tambien utiliza
el ejecutable de R para hacer la integracion...se veia muy prometedor...sin
embargo, R.NET aun esta en desarrollo y por alguna razon sin sentido...no podia
hacerlo funcionar puesto que el .dll no podia ser encontrado por el motor de
.NET...pense...bueno...quizas es culpa de PowerBuilder...vamos a probar en un
verdadero entorno .NET...asi que instale
Visual Studio Express 2012 for Desktop...la misma suerte...el
.dll no podia ser encontrado...
Estaba cansado y molesto...nada parecia
funcionar...pero cuando regrese a la pagina de Rserve me di cuenta de que habia
un proyecto .NET llamado
RserveCLI que utilizaba Rserve para hacer la integracion con
R....cuando descargue el proyecto...no habia ninguna .dll disponible, pero eso
no era ningun problema...puesto que simplemente lo compile en VS Express y
obtuve una brillante .dll lista para ser probada...asi que cree un nuevo
proyecto de C# Console y lo probe...funciono perfectamente...
Cuando
intente utilizarlo en PowerBuilder.NET por primera vez...no funciono...asi
que...como se imaginaran...estaba aun mas cansado y aun mas molesto...y por
alguna razon inexplicable...termine borrando un archivo insignificante del .NET
framework que simplemente malogro todo...ya no podia ejecutar PowerBuilder o VS
Express...suerte maldita...otro viaje para arreglar mi desastre...Desinstale
todas las referencias del .NET framework...compiladores
VC++...Runtimes...etc...me tomo casi un dia completo para finalmente tener todo
de vuelta y en su sitio...sin embargo...hasta el dia de hoy...VS Express murio
completamente...no puedo ni siquiera instalarlo nuevamente...puesto que el
instalador me muestra la pantalla del VS por unos segundos y luego desaparece
sin ningun mensaje de error aparente...
En fin...por lo menos
PowerBuilder estaba funcionando nuevamente...y finalmente supere mis problemas
con el RserveCLI dll...
El programa que voy a mostrarles, es sin duda
alguna bastante simple...tanto por la naturaleza de la integracion...como por el
hecho de que RserveCLI aun esta en desarrollo...no hay realmente mucho que
podamos hacer...pero aun asi...pienso que ayuda a ilustrar dos puntos
interesantes...
- PowerBuilder.NET puede interactuar con archivos .dll de .NET
- R puede ser utilizado por una amplia gama de lenguajes de
programacio
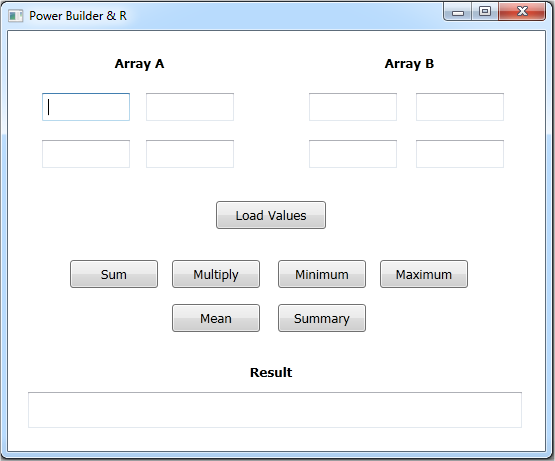
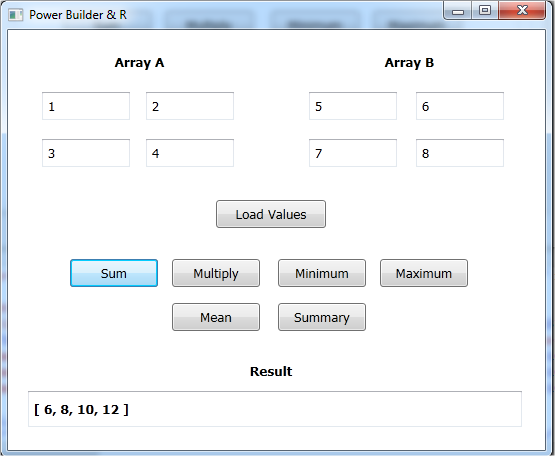
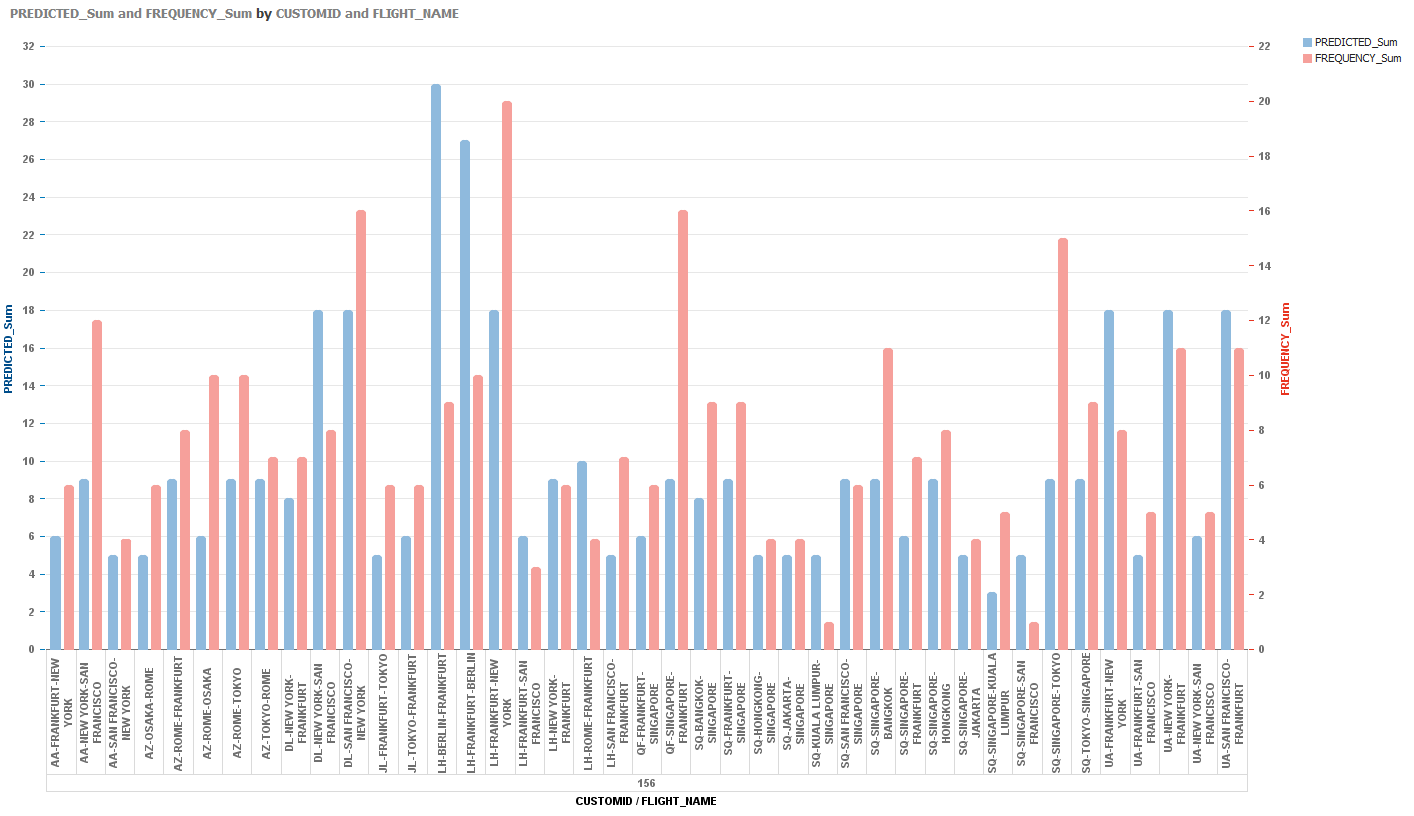
Este programa nos va a pedir que llenemos dos arrays, Array A y Array
B...cada uno con cuatro elementos (de alguna manera...y por alguna razon que
sigo intentado comprender...cuando llamamos a R desde PowerBuilder, necesitamos
pasar un array bi-dimensional arrays...siendo el minimo [2,2]...)
Veamos el layout...
Asi que...basta de hablar...vamonos al codigo fuente...
Primero, vamos a definir una variable global puesto que vamos a utilizarla
en muchos lugares...
| Global Variables |
RserveCli.RConnection conn
|
|
Luego, vamos a llamar al evento Open de la ventana
principal (w_window).
| w_window.Open |
#if DEFINED PBDOTNET then
@System.Net.IPAddress ipadd
byte ip[4] = {127,0,0,1}
ipadd = create @System.Net.IPAddress(ip)
@System.Int32 port
port = create System.Int32
port = 6311
conn = create RserveCli.RConnection(ipadd,port,"","")
#end if
|
|
Aqui, estamos diciendo que vamos a utilizar codigo
al estilo de .NET, asi que deberia ser ignorado por el compilador de
PowerBuilder...como estamos utilizando Rserve en nuestra laptop, utilizamos la
direccion IP del localhost y asignamos el puerto por defecto de Rserve que es
6311. Definimos una conexion con el servidor utilizando el metodo RConnection.
Si se preguntan por que estoy utilizando la @ es porque quiero estar seguro de
que estoy llamando al System de .NET y no de PowerBuilder...Yo se que dije que
el compilador de PowerBuilder deberia ignorarlo...pero es mejor prevenir que
lamentar....
Tenemos un boton llamado cb_load que va a cargar los arrays
definidos en la pantalla.
| cb_load.Clicked |
double varA[2,2], varB[2,2]
varA[1,1] = double(Array_A_1.Text)
varA[1,2] = double(Array_A_3.Text)
varA[2,1] = double(Array_A_2.Text)
varA[2,2] = double(Array_A_4.Text)
varB[1,1] = double(Array_B_1.Text)
varB[1,2] = double(Array_B_3.Text)
varB[2,1] = double(Array_B_2.Text)
varB[2,2] = double(Array_B_4.Text)
#if DEFINED PBDOTNET then
::conn["A"] = RserveCli.Sexp.Make(varA)
::conn["B"] = RserveCli.Sexp.Make(varB)
#end if
|
|
Aqui, simplemente creamos dos arrays y los
llenamos. Llamamos a ::conn con el extra "::" para dejarle saber al
compilador que es una variable global. Cuando utilizamos el Sexp.Make estamos
diciendo que queremos crear un vector de R utilizando el array que pasamos como
parametro. Asi que un vector llamdo A and y otro llamado B.
Ahora que
tenemos los arrays cargados en memoria, podemos proseguir con los otros
botones.
| cb_sum.Clicked |
#if DEFINED PBDOTNET then
txtResult.Text = ::conn["A+B"].ToString()
#end if
|
|
Esto es bastante simple, simplemente estamos
diciendo...envia el comando "A+B" a R y dame el resultado como un String. En R,
A+B va a producir un suma de vectores...lo cual significa que en vez de crear un
factor conteniendo los valores de A y B, va a tomar el primer elemento de
A y sumarlo con el primer elemento de B, va a hacer lo mismo con el resto de los
elementos. Ven a ver esto mas claramente, mas adelante.
| cb_multiply.Clicked |
#if DEFINED PBDOTNET then
txtResult.Text = ::conn["A*B"].ToString()
#end if
|
|
Esto es basicamente lo mismo, con la excepcion de
que vamos a multiplicar en vez de sumar.
| cb_min.Clicked |
#if DEFINED PBDOTNET then
RserveCli.Sexp varC = ::conn["min(c(A,B))"]
txtResult.Text = varC.ToString()
#end if
|
|
Esto es un poco mas interesante...vamos a crear una
variable Sexp y luego ejecutar una operacion en R...al hacer "c(A,B)" vamos a
tomar los elementos de B y agregarlos a A, asi que A va a contener los valores
de ambos...al utilizar "min()" vamos a obtener el valor minimo.
| cb_max.Clicked |
#if DEFINED PBDOTNET then
RserveCli.Sexp varC = ::conn["max(c(A,B))"]
txtResult.Text = varC.ToString()
#end if
|
|
Aqui es la mista historia, pero vamos a obtener el
valor maximo en vez del minimo.
| cb_mean.Clicked |
#if DEFINED PBDOTNET then
RserveCli.Sexp varC = ::conn["mean(c(A,B))"]
txtResult.Text = varC.ToString()
#end if
|
|
La misma historia nuevamente...R es realmente facil
de usar...calculamos el promedio que simplemente va a ser la suma de los
elementos divida por la cantidad de elementos.
| cb_summary.Clicked |
#if DEFINED PBDOTNET then
RserveCli.Sexp varC = ::conn["summary(c(A,B))"]
string varS = "Min: " + varC[0].ToString() + " / 1st Qu: " + varC[2].ToString() + " / Median: " &
+ varC[2].ToString() + " / Mean: " + varC[3].ToString() + " / 3rd Qu: " &
+ varC[4].ToString() + " / Max: " + varC[5].ToString()
txtResult.Text = varS
#end if
|
|
Aqui, vamos a obtener el summary de mezclar A y B.
El summary es una variable compleja que va a retornarnos los valores minimo y
maximo, el 1er y 3er quadrantes, la media y el promedio. Simplemente llamandolo
como un array, podemos extraer todos los valores...
Finalmente...y para
hacer que nuestro programa se ejecute...necesitamos llamar al ultimo pedazo de
codigo...
| wfpapp.Open |
open(w_window)
|
|
wpfapp es el nombre de nuestra aplicacion (por
defecto de PowerBuilder). Aqui decimos, abre nuestra ventana principal llamada
w_window (otro por defecto de PowerBuilder)...
Ejecutemos la aplicacion y
veamos como funciona...
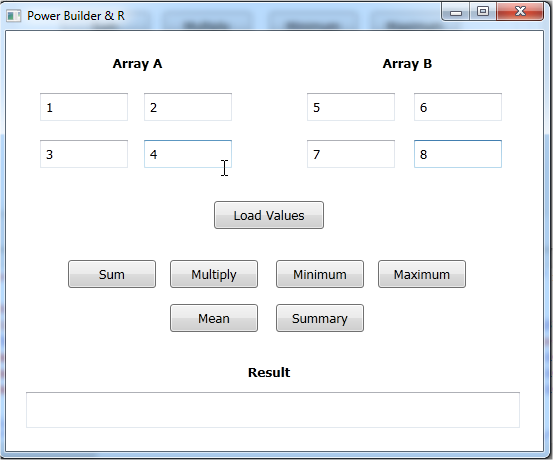
Estamos simplemente llenado las cajas de texto con
datos inventados...Array A va a contener 1,2,3,4 y Array B va a contener
5,6,7,8.
Cuando presionamos
el boton sum...1 y 5 van a sumarse, 2 y 6 van a sumarse, 3 y 7 van a sumarse y
finalmente, 4 y 8 van a sumarse.
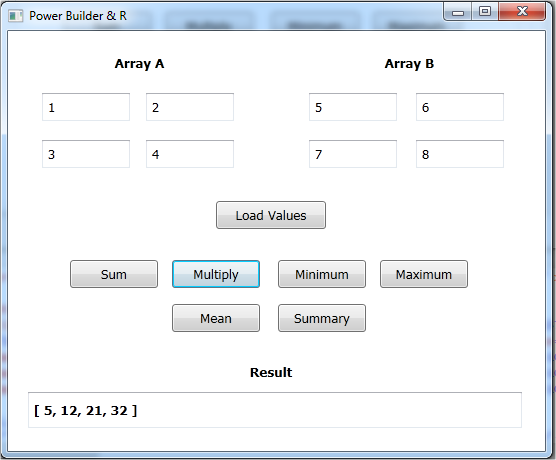
Cuando presionamos
el boton Multiply, lo mismo va a pasar, pero los numeros van a ser multiplicados
en vez de ser sumados.
Ya deben saber que pasa cuando presionamos los botones Minimum, Maximum y
Mean...asi que vamos a movernos directamente al boton Summary. los
valores minimo y maximo, el 1er y 3er quadrantes, la media y el
promedio
Comp pueden ver...este es un ejemplo muy simple...pero creanme...despues de
4 dias completos de trabajo...estoy feliz de finalmente haberlo hecho
funcionar...y ustedes pensaban que mi trabajo era sencillo? Pienselo de nuevo
-;) 4 dias y noches de full stress...
Saludos,
Blag.